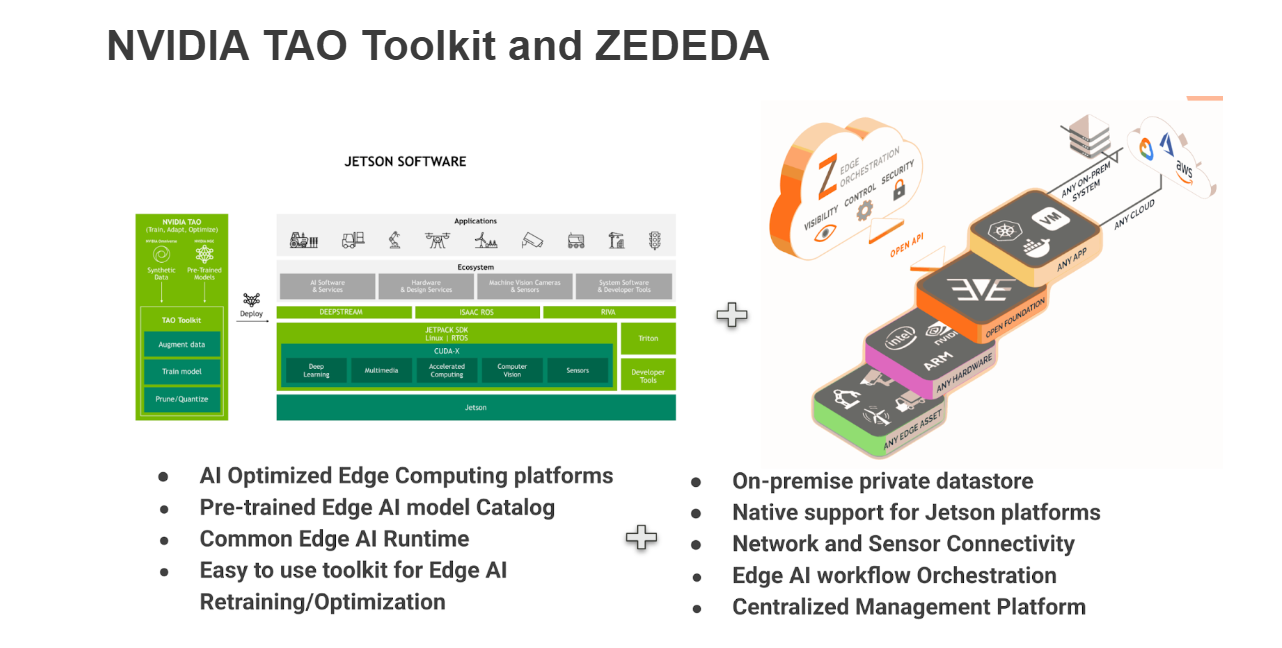
How ZEDEDA extends Kubernetes to simplify AI deployment across diverse edge environments
AI workloads are moving closer to the data they analyze. But running AI at the edge introduces a new set of challenges, including limited bandwidth, unpredictable connectivity, data privacy requirements, and the sheer diversity of hardware. As ZEDEDA Distinguished Engineer Hariharasubramanian C. S. explains in this Edge Field Day showcase, sending every sensor stream to the cloud for inference simply isn’t practical. The smarter, more efficient approach is to bring AI to the edge itself, without giving up control or manageability.
This session demonstrates how ZEDEDA Edge Kubernetes Service enables teams to deploy and operate AI workloads directly on edge devices, ensuring each model runs close to the data source while remaining easy to provision, update, and monitor at scale.
Running AI Closer to the Data
Edge AI delivers immediate insights, but it also demands autonomy. Deployments must continue to function even when offline, handle diverse GPUs and processors, and securely manage local model storage. ZEDEDA addresses these realities with a lightweight, cloud-managed Kubernetes architecture designed specifically for the edge.
The presentation highlights how Kubernetes streamlines the packaging and management of the many components that make up an AI pipeline, from preprocessing and inference to postprocessing, monitoring and API management. ZEDEDA extends those capabilities to the edge, offering full lifecycle control while maintaining flexibility across hardware types and environments.
Simplifying AI Pipeline Deployment with Kubernetes
Using a car classification example, the demonstration shows how ZEDEDA simplifies deploying and managing multi-component AI applications at the edge. The solution packages an OpenVINO inference server, a model-pulling sidecar, and a demo client application into a single Helm chart that can be deployed through the ZEDEDA Edge Kubernetes Service.
From the ZEDEDA control plane, users can provision clusters, deploy workloads, and manage updates automatically. Model files remain stored securely in private, on-premise networks, ensuring sensitive IP never leaves the edge environment, while the ZEDEDA controller maintains observability and state awareness across every node. The result is a streamlined workflow: models can be refreshed, applications updated, and performance monitored without direct access to individual devices.
Open Ecosystem and Developer Freedom
ZEDEDA’s open approach means developers aren’t locked into a proprietary stack. Users can integrate their own Helm charts, connect to private or third-party repositories, and take advantage of ZEDEDA’s open source edge AI examples to jump-start new use cases. The Edge Kubernetes Service maintains compatibility with upstream versions and supports low-footprint distributions like K3s, allowing workloads to run even on constrained hardware such as Jetsons or industrial gateways.
One Platform for AI at Scale
Together, these capabilities illustrate how ZEDEDA enables consistent AI operations from the data center to the far edge. Whether managing a small single-node cluster or coordinating thousands of distributed inference devices, ZEDEDA delivers the same zero-touch provisioning, policy-based orchestration, and secure model management across environments.
Watch the full Edge Field Day demo to see how ZEDEDA Edge Kubernetes Service simplifies Edge AI deployment, making it easy to run and manage complex AI workloads anywhere data is generated.