

A Technical Deep-Dive into Distributed AI at the Edge
Introduction
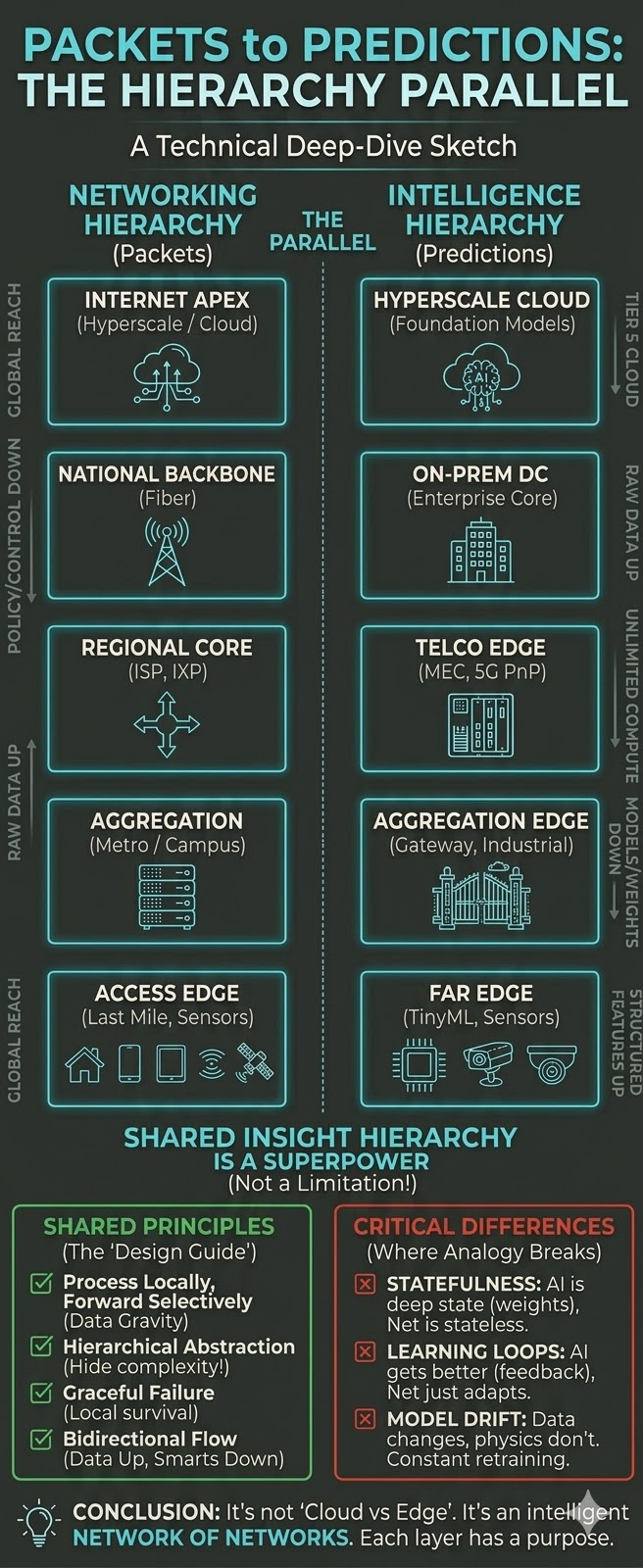
There is a profound architectural parallel hiding in plain sight between two of the most consequential infrastructure disciplines of our time: data networking and distributed AI/ML. Both have independently converged on the same fundamental insight: that hierarchy is not a limitation, but a superpower.
For decades, network engineers have structured the flow of data across a disciplined hierarchy: from access switches at the periphery, through aggregation and distribution layers, across core backbones, and ultimately into the global Internet. Each layer serves a distinct purpose: proximity, aggregation, policy enforcement, and scale.
Today, as AI and ML workloads push intelligence from centralized cloud data centers into the physical world, the same hierarchical logic is reasserting itself. Intelligence, like data before it, must be structured in layers, with each optimized for latency, bandwidth, compute density, power, and connectivity constraints at that tier. Put another way: hierarchical intelligence mirrors the architecture of data networks.
This post draws the map between these two hierarchies and argues that understanding one is the key to mastering the other.
Part I: The Layered Architecture of Data Networking
Before drawing the analogy, let us establish the canonical networking hierarchy — both within data centers and across the broader Internet.
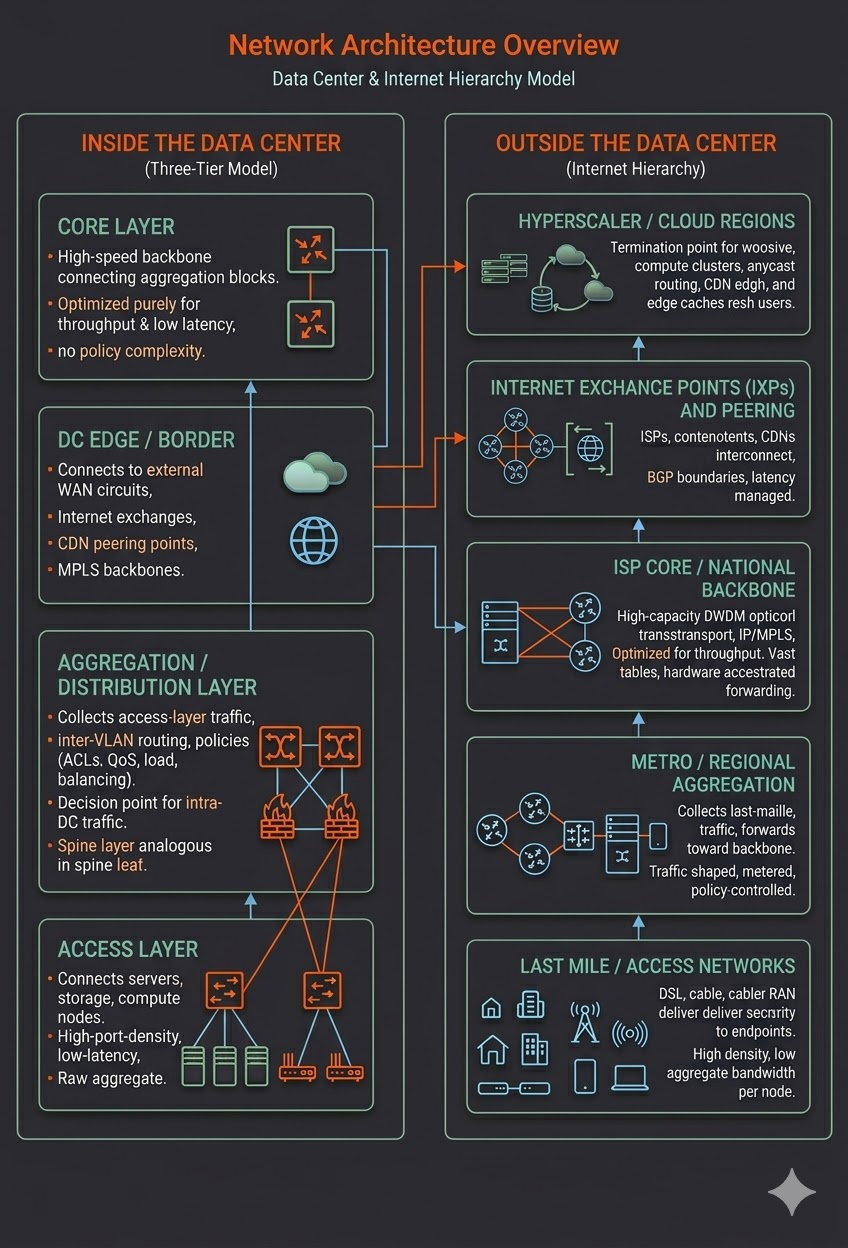
Inside the Data Center: The Three-Tier Model
Modern data centers (and their more scalable successors, spine-leaf fabrics) are built on a clear separation of concerns:
Access Layer: Where servers, storage, and compute nodes connect. These switches are high-port-density, low-latency devices optimized to carry traffic from endpoints into the fabric. They do minimal policy work; their job is raw connectivity.
Aggregation / Distribution Layer: Where access-layer traffic is collected, inter-VLAN routing occurs, and policies (ACLs, QoS, load balancing) are enforced. This layer is the decision point for intra-data-center traffic flows. In spine-leaf architectures, the spine layer plays an analogous role.
Core Layer: The high-speed backbone connecting aggregation blocks to the data center’s edge routers. Optimized purely for throughput and low latency; no policy complexity here.
Data Center Edge / Border: Where the data center connects to external networks: WAN circuits, Internet exchanges, CDN peering points, and MPLS backbones.
Outside the Data Center: The Internet Hierarchy
The broader Internet replicates this layered thinking at planetary scale:
- Last Mile / Access Networks: DSL, cable, fiber, and cellular RAN (Radio Access Network) deliver connectivity to homes, businesses, and mobile devices. High endpoint density, relatively low aggregate bandwidth per node.
- Metro/Regional Aggregation: ISP aggregation routers, DSLAM headends, and mobile packet gateways collect last-mile traffic and forward it to the backbone. Traffic is shaped, metered, and policy-controlled here.
- ISP Core / National Backbone: High-capacity DWDM optical transport and IP/MPLS core routers optimized for throughput. Routing tables are vast; forwarding must be hardware-accelerated.
- Internet Exchange Points (IXPs) and Peering: Where ISPs, content providers, and CDNs interconnect. Traffic handoffs occur at BGP (Border Gateway Protocol) boundaries. Latency is managed at the peering tier.
- Hyperscaler / Cloud Regions: The termination point for most modern workloads. Massive compute clusters, global anycast routing, and CDN edge caches reach back toward users.
The key insight: each layer processes what it can locally and forwards only what it must upward (or northbound). A home router handles DHCP locally. An ISP aggregation node handles per-subscriber QoS locally. A national backbone never sees individual subscriber sessions — only aggregated flows.
Part II: The Emerging Hierarchy of Distributed Intelligence
Now consider the analogous hierarchy forming in the world of AI and ML inference — from physical sensors at the edge to hyperscale GPU clusters in the cloud.
Tier 1: Far Edge (Device / Sensor Edge)
Networking analog: End devices and access-layer endpoints.
The far edge sits at the point of data generation: industrial sensors, cameras, robots, autonomous vehicles, smartphones, medical monitors, and IoT gateways. Compute here is severely constrained — microcontrollers, small SoCs, and embedded neural accelerators (NPUs) running quantized, compressed models.
Intelligence at the far edge is necessarily narrow, fast, and local. A vibration sensor running a tiny anomaly detection model does not send raw time-series waveforms to the cloud — it sends a flag: “bearing wear detected.” A smart camera running MobileNet or a YOLO nano model classifies objects locally and forwards only bounding boxes and class labels, not raw video frames.
This mirrors the access-layer switch: it does not forward raw electrical signals — it frames, packetizes, and forwards only structured data. The intelligence (or forwarding logic) at this layer is minimal but purposeful.
Characteristics: Ultra-low latency (sub-millisecond inference), severe power and thermal constraints, disconnected or intermittent connectivity tolerance, TinyML and quantized model formats (TFLite, ONNX Runtime, or OpenVINO) on small devices.
Tier 2: Aggregation Edge (On-Premises Gateway / Industrial Edge)
Networking analog: Aggregation/distribution layer switches.
The aggregation edge is where streams from many far-edge devices converge. This is the industrial PC on a factory floor, the edge server in a retail store, the ruggedized gateway in a utility substation, or the multi-access edge compute (MEC) node in a cellular base station cluster. Compute here is meaningful — GPU-equipped edge servers, NVIDIA Jetson AGX-class hardware, or x86 servers with hardware accelerators.
At this tier, intelligence becomes contextual and correlative. Rather than analyzing a single sensor, the aggregation edge can fuse data from dozens of sensors. An anomaly from one bearing can be correlated with temperature spikes from an adjacent motor and vibration patterns from a connected shaft — enabling root-cause analysis that no single far-edge device could perform on its own.
This is also where model management begins: models can be updated over the air, A/B tested, and monitored. Data can be selectively buffered for later upload to higher tiers when connectivity is available.
Characteristics: Moderate latency (single-digit milliseconds), GPU/NPU acceleration, capable of running medium-complexity models (ResNet, BERT-base, or time-series transformers), local data store for buffering, connectivity to both far-edge devices and upper tiers.
Tier 3: On-Premises Data Center Edge (Campus / Enterprise Datacenter)
Networking analog: The data center core and Datacenter edge/border routers.
Many large enterprises, hospitals, manufacturers, and financial institutions operate their own on-premises data centers — not hyperscale, but substantial. These are the tiers where significant AI training (fine-tuning, transfer learning), complex batch inference, and data management workloads run.
Intelligence at this tier is strategic and comprehensive. An on-premises datacenter might run digital twin simulations of an entire factory floor, train production-quality models on proprietary data that cannot leave the premises for regulatory reasons, or run large-scale inference pipelines that aggregate results from dozens of aggregation edge nodes.
The on-prem datacenter also serves as the policy and governance boundary — analogous to the DC border router that enforces security, firewall, and routing policies. At this layer, AI governance (model versioning, bias auditing, explainability logging, data lineage) is enforced before workloads or data are permitted to flow upward to external tiers.
Characteristics: Substantial GPU clusters with A100/H100 scale, high-bandwidth internal networking (100GbE/400GbE), on-premises MLOps pipelines, strong regulatory compliance controls, capable of hosting large models (LLaMA-class, domain-specific foundation models), and latency in the tens of milliseconds for complex inference.
Tier 4: Telco Edge (MEC / Regional Edge)
Networking analog: ISP regional aggregation, IXPs, and carrier-grade infrastructure.
Telco edge — also called Multi-access Edge Compute (MEC) as defined by ETSI — represents compute resources embedded within or co-located with cellular network infrastructure (5G gNBs, 4G eNBs, or regional PoPs). This is the carrier’s edge cloud: geographically distributed, interconnected by carrier-grade MPLS and optical transport, and positioned to serve an entire metro area or region.
This tier is particularly powerful because of its network-native positioning. A telco MEC node “sees” mobile traffic before it traverses the Internet. Ultra-low-latency AI services (AR/VR rendering, autonomous vehicle coordination, drone fleet management, real-time video analytics across a city) that cannot tolerate transcontinental round-trips to a hyperscaler cloud find their home here.
The telco edge also plays the orchestration and brokering role analogous to IXP peering: it decides which workloads to handle locally, which to forward to the enterprise’s on-prem datacenter, and which to offload to the cloud. Network slicing in 5G allows dedicated compute and bandwidth resources to be carved out per-tenant, per-SLA — precisely as QoS policies are enforced at ISP aggregation points.
Characteristics: Carrier-grade reliability (99.999% availability targets), sub-10ms latency to 5G-connected devices, mid-range GPU/FPGA accelerators, multi-tenant orchestration (Kubernetes on bare metal), tight integration with 5G core (UPF, SMF), geographic distribution across dozens to hundreds of PoPs per country.
Tier 5: Hyperscale Cloud
Networking analog: Hyperscaler backbone, anycast CDN infrastructure, and Internet core.
The cloud is the apex of the intelligence hierarchy, just as the hyperscaler backbone is the apex of the networking hierarchy. AWS, Azure, Google Cloud, and their peers operate at a scale that no other tier can match: hundreds of thousands of the latest-generation GPUs and TPUs, exabytes of storage, global private backbone networks, and the engineering depth to build and maintain foundation models at the frontier of AI capability.
At this tier, intelligence is foundational and generative. GPT-4, Gemini, Claude, Llama 3, and their successors are trained and served here. Massive data lakes from all lower tiers are ingested, cleaned, and used to improve models continuously. Global A/B testing, reinforcement learning from human feedback (RLHF), and large-scale hyperparameter search are economically viable only at cloud scale.
The cloud also plays a global coordination role: distributing updated model weights back down the hierarchy to lower tiers, maintaining the authoritative registry of model versions, aggregating federated learning updates from edge nodes while preserving privacy, and providing the “ground truth” for any intelligence that needs to be globally consistent.
Characteristics: Virtually unlimited compute and storage, proprietary AI accelerators, such as TPUs, Trainium, and Gaudi, global anycast routing for inference APIs, PB-scale training runs, highest latency from physical endpoints (50–200ms transcontinental), full MLOps platform (AWS SageMaker, Google Vertex AI, Microsoft Azure ML), model registry and governance at global scale.
Part III: The Structural Parallels — A Side-by-Side Comparison
| Dimension | Networking Hierarchy | Intelligence Hierarchy |
| Outermost tier | End devices/access switches | Far Edge (sensors, TinyML) |
| First aggregation | Aggregation/distribution layer | Aggregation Edge (industrial gateway) |
| Local backbone | Data center core/campus core | On-prem datacenter |
| Carrier-grade regional | ISP regional / MEC PoP | Telco Edge (MEC) |
| Global apex | Hyperscaler backbone / Internet core | Cloud (hyperscaler AI) |
| Primary optimization at the leaf | Low latency, high port density | Ultra-low latency, minimal power |
| Primary optimization at the core | Throughput, resilience | Scale, generality |
| What flows upward | Aggregated, abstracted traffic | Refined features, model updates, anomalies |
| What flows downward | Routing updates, policy | Model weights, configurations, labels |
| Policy enforcement layer | Distribution/Datacenter border | On-prem datacenter / Telco Edge |
| Failure domain isolation | VLANs, routing boundaries | Federated learning, local inference fallback |
| Latency budget | Microseconds → milliseconds → hundreds of ms | Sub-ms → single-digit ms → 50–200ms |
Part IV: Key Architectural Principles Common to Both
1. Process Locally, Forward Selectively
In networking, a switch does not flood all traffic to all ports — that was the old hub model, which collapsed under load. Instead, it learns, filters, and forwards only what must traverse the next boundary.
In AI, the same principle applies. A far-edge camera does not stream raw 4K video to the cloud for object detection. It runs inference locally and forwards only structured results. The aggregation edge doesn’t send raw sensor telemetry to the cloud — it forwards anomaly scores, trend summaries, and critical events. This is data gravity in action: compute moves to where data is born, not the other way around.
2. Hierarchical Abstraction
Networks abstract physical complexity behind logical interfaces. A router speaks BGP to its peers — it does not need to know that a packet traveled over single-mode fiber through a DWDM mux before arriving. The abstraction boundary is clean.
Distributed AI creates analogous abstractions. The cloud does not need to know that a prediction came from a Cortex-M55 microcontroller in a 50°C factory floor environment. It receives a structured inference result. Federated learning abstracts training data entirely — the cloud receives gradient updates, never raw data.
3. Failure Domain Isolation and Graceful Degradation
A well-designed network continues to function when a regional ISP goes down — traffic reroutes, BGP reconverges, and edge locations stay up. Edge nodes never have a single point of failure to the Internet.
Distributed AI must be equally resilient. A far-edge node must be able to run inference locally when its uplink to the aggregation edge fails. The aggregation edge must serve local users when the WAN to the on-prem datacenter is severed. Each tier must have a defined offline fallback posture — running a cached, potentially less-accurate model rather than failing hard.
4. Policy and Governance at the Boundary
Networks enforce security and routing policy at well-defined points: firewalls at the datacenter edge, ACLs at the distribution layer, and BGP route filters at peering boundaries.
AI governance must follow the same discipline. Data that cannot leave an enterprise (for GDPR, HIPAA, or competitive reasons) is processed and stays within the on-prem datacenter boundary. Federated learning enforces this at the cryptographic level. The telco edge enforces tenant isolation between competing enterprises sharing MEC infrastructure, just as VRFs isolate customers on a shared MPLS backbone.
5. Bidirectional Traffic: Not Just Upload
Networks are not one-way. Routing updates, ARP broadcasts, spanning tree BPDUs, and control-plane traffic flow in all directions. The hierarchy carries both data-plane and control-plane traffic.
The intelligence hierarchy is equally bidirectional. Data and features flow upward for aggregation and training. But model weights, configurations, software updates, and labeling instructions flow downward. Orchestration signals (start inference job, retrain on new data, update preprocessing pipeline) flow downward from MLOps control planes. This two-way flow is fundamental — the hierarchy is not a pipeline, it is a distributed control system.
Part V: Where the Analogy Breaks Down, and Why That Matters
Every analogy has limits, and understanding where this one breaks down is itself instructive.
State vs. Statelessness. Core network routers are designed to be as stateless as possible — they forward packets based on destination addresses, maintain no per-flow state (in the pure IP model), and are therefore horizontally scalable. AI models are deeply stateful — the weights of a neural network encode the distilled history of all training data. Managing this state across a hierarchy (versioning, consistency, rollback) is a problem networking never had to solve at this level of complexity.
Feedback Loops and Learning. Networks adapt via control protocols (OSPF, BGP reconvergence), but they do not learn in the machine learning sense — a router does not get better at routing over time by observing traffic. AI hierarchies are designed around continuous learning feedback loops: predictions at the far edge generate labeled data (via human review or automated oracles) that flows upward to retrain models, which then flow back downward as improved weights. This learning loop is the core value driver and has no direct networking analog.
Model Drift and Non-Stationarity. Network topology changes, but its physics are stable. A packet traveling on fiber obeys the same laws today as it did a decade ago. AI models degrade as the world changes, when production data distributions shift, new object categories appear, and language evolves. The intelligence hierarchy must constantly detect drift, trigger retraining, and propagate updated models. This is an ongoing operational burden that networking infrastructure does not face.
Conclusion: Building the Intelligent Network of Networks
The architects of the early Internet made a decision that proved enormously consequential: to build a hierarchy of abstraction layers, each doing what it does best and forwarding only what it must. The result was a network that scaled from ARPANET to the global Internet without a fundamental redesign.
The architects of distributed AI are making the same bet today. Far-edge TinyML, aggregation-edge inference servers, on-prem ML clusters, telco MEC platforms, and hyperscale cloud GPUs are not competing approaches — they are layers in a coherent hierarchy. Each tier is necessary. Each handles what it is positioned to handle. Together, they form an intelligent network of networks — one where the question is not “cloud vs. edge” but rather “which layer of the hierarchy serves this workload best, and how do layers cooperate to serve the workloads that span tiers?”
The networking analogy is more than a metaphor. It is a design guide. The lessons of thirty years of hierarchical network architecture — about abstraction, local processing, graceful degradation, policy boundaries, and bidirectional control planes — are directly applicable to the distributed intelligence infrastructure being built today.
The packets and the predictions are on the same journey. They just carry different cargo.
Next Steps
If you need to build your Edge AI platform, ZEDEDA can help. Our Edge Intelligence Platform combines an AI-driven approach to build and orchestrate edge agents, models, applications, and infrastructure. This lets you build, test, and deploy AI agents and models on any edge hardware, using the same edge orchestration platform trusted by the world’s largest enterprises. Get in touch at https://zededa.com/contact-us/.
FAQ
Q: Doesn’t every AI workload just end up in the cloud anyway? Why bother with a hierarchy?
A: The same question was asked about networking in the 1980s: Why not just route everything through a central hub? The answer then, as now, is physics and economics. The speed of light bounds latency. A factory robot that needs a sub-millisecond safety decision cannot wait 80ms for a transcontinental round trip to AWS. Beyond latency, raw data volumes at the edge are staggering; a single high-resolution industrial camera generates roughly 2GB per minute. Sending that upstream continuously is neither economically viable nor necessary when a local model can reduce it to a handful of structured events per second. The hierarchy exists for the same reason the Internet hierarchy exists: because not every problem belongs at the top.
Q: How do I decide which tier to target for a given AI workload?
A: Start with three questions:
- First, what is the maximum tolerable latency? Sub-millisecond means Tier 1 (far edge). Single-digit milliseconds means Tier 2 (aggregation edge). Tens of milliseconds are workable at Tier 3 (on-prem datacenter).
- Second, can the data leave the premises? Regulatory constraints (HIPAA, GDPR, competitive sensitivity) anchor workloads to the lowest tier that satisfies them.
- Third, how large is the model, and how often does it change? A 70B-parameter foundation model cannot run on a microcontroller; a quantized MobileNet variant cannot perform a legal document summarization task.
Match model complexity to the compute available at the candidate tier, and you have your answer.
Q: What is the practical equivalent of “offline fallback posture” for an edge AI system?
A: In networking terms, it is the default route of last resort: when all else fails, keep forwarding. For edge AI, this means every tier must have a locally cached model capable of running inference without any upstream dependency. The model may be smaller, less accurate, or have a narrower scope than the full production model. That is acceptable. What is not acceptable is a hard failure: a factory inspection system that stops working entirely when the WAN link drops is not production grade. The design principle is the same as BGP graceful restart: preserve the data plane even when the control plane is unreachable.
Q: How does model versioning and rollout across this hierarchy compare to software deployment in traditional distributed systems?
A: It is significantly harder. In a traditional microservices rollout, you push a new container image and the runtime handles the rest. In a distributed AI hierarchy, the “artifact” being deployed is a model checkpoint that may be gigabytes in size. Or, the target devices may have intermittent connectivity. Or, a bad model does not throw an exception but instead silently produces wrong predictions. This makes canary deployments and A/B testing essential rather than optional. The aggregation edge is the natural place to implement this: it can run two model versions simultaneously on different subsets of far-edge devices, compare confidence distributions, and promote or roll back without touching the cloud tier. Think of it as the equivalent of a staged BGP route announcement: you do not push a new route to the full Internet before you have validated it on a subset of peers.
Q: The post draws an analogy between VRFs on an MPLS backbone and tenant isolation at the telco edge. How deep does that analogy go in practice?
A: Reasonably deep. A VRF assigns each tenant its own routing table, preventing overlapping IP address spaces from colliding and traffic from leaking across tenant boundaries. At the telco MEC tier, 5G network slicing does the same thing for compute and bandwidth: each slice has its own guaranteed resource allocation and its own traffic isolation boundary. The practical implication for architects is that multi-tenant MEC deployments require the same discipline as multi-tenant MPLS: explicit data-plane isolation, separate control planes per tenant, and auditable boundaries for compliance. Where the analogy breaks down is state: a VRF is stateless per packet, while an AI inference workload carries significant per-tenant state (model weights, inference context, calibration parameters) that must be managed separately.
Q: Federated learning is mentioned as the privacy-preserving mechanism for the cloud aggregation tier. What are the architectural gotchas?
A: Several. First, gradient updates are not as privacy-preserving as they appear: membership inference attacks can reconstruct training samples from gradients with sufficient access. Production deployments typically add differential privacy noise to gradients before they leave the edge tier, introducing a trade-off with model accuracy. Second, federated aggregation assumes all participating nodes are running compatible model architectures. A version skew between a far-edge node on an old firmware and the cloud aggregator can produce gradients that are simply incompatible, requiring the aggregator to reject or quarantine that node’s contribution. Third, the communication cost of gradient synchronization is non-trivial: for a large model, even compressed gradients can be hundreds of megabytes per round. Scheduling this traffic to avoid congesting the uplink at peak production hours is an operational concern that maps directly to traffic shaping at the ISP aggregation tier.
Q: Where does orchestration software like Kubernetes fit into this hierarchy, and does it span tiers?
A: Kubernetes was designed for the data center tier and works well there. At the far edge, it is generally too heavy: a microcontroller running TinyML does not run a kubelet. The aggregation edge is where Kubernetes (or its lightweight variant, K3s) becomes viable: local clusters of a few nodes that manage inference workloads, model-serving containers, and data buffering.
The harder question is cross-tier orchestration: do you want a single control plane that spans Tier 1 through Tier 5? The networking analogy is instructive here, too. You do not run a single routing protocol from your access switch to the Internet core. You run separate protocols at each tier with well-defined redistribution points. The same discipline applies to AI orchestration: a local edge orchestrator manages far-edge and aggregation-edge workloads, with a higher-level MLOps control plane at the on-prem datacenter or cloud tier issuing policy (which model version to run and what data to retain) rather than issuing direct operational commands.
Q: The post argues that the intelligence hierarchy is a distributed control system, not a pipeline. What does that change about how you design it?
A: It changes everything about fault tolerance and consistency modeling. A pipeline has a clear upstream and downstream: if one stage fails, the pipeline stalls. A distributed control system has no single point of authority. Each tier must be able to operate autonomously when its connections to adjacent tiers are severed, and must reconcile its state when connectivity is restored. This means each tier needs its own local policy store (the cached model and its configuration), its own local decision authority (it can serve inference requests without asking permission), and a well-defined reconciliation protocol for when the control plane reconnects (analogous to BGP session reestablishment after a link flap). Architects who treat edge AI as a simple request-response pipeline to the cloud will build systems that fail in exactly the scenarios where edge intelligence is most valuable: when connectivity is degraded, intermittent, or absent.



