
First, it was “big data.” Then came “AI,” “blockchain,” and the “Internet of Things.” In an attempt to categorize the complex and varied emerging technologies coming out of our industry, the proliferation of buzzwords has created well-earned skepticism on what will be “the next big thing” and how it will actually have an impact.
It’s understandable. Most companies starting out tend to beat their chests about how great they are and don’t spend much time connecting the dots between all that greatness and actual business outcomes. With so much jargon being thrown out there (Product X will unlock Y to accomplish Z), I wanted to sit down and get real on what “cloud-native edge computing at hyperscale” means.
Edge computing is what makes real-time reaction to IoT data possible. That’s because it eliminates latency, bandwidth, and autonomy limitations of cloud that can hamper or destroy real-time applications. However, edge computing as it stands today has never contemplated a connected, “hyperscale” world. Unlike cloud, edge computing is still very rooted in the world of embedded computing and processing. This world wasn’t intended to achieve application lifecycle management at hyperscale like the cloud is architected for. The embedded world is less accustomed to the networked systems, security, and app management that solve the problems of deploying, managing, and securing apps at hyperscale.
Of course, applications do exist today in the embedded computing world that are autonomous and real-time, and that interact with the physical world. Examples include programmable logic controllers (PLCs) on an assembly line controlling robots or in a solar farm controlling power systems.
However, these embedded systems have operating limitations that — when viewed from the scale, security, and network requirements of an IoT world — make it hard to create a consistent approach to deploying, securing, updating, and future-proofing them, especially over-the-air at remote locations, without an unrealistic increase in operational costs.
The era of cloud computing introduced app developers to the concept of “cloud-native” applications: a model where developers are more concerned with how apps are created, deployed, and maintained at hyperscale, and not concerned with “where” they are physically deployed. Application developers can focus on continuous, agile delivery of software with a base assumption that infrastructure should be taken for granted. “Cloud-native” at the edge extends this base assumption to enable agile development regardless of the network topology, geography, or hardware diversity found at the edge.
Examining the software application lifecycle at the edge today versus a “cloud-native” approach highlights the fundamental differences that an edge app platform must achieve to provide continuous delivery at distributed locations and at hyperscale.
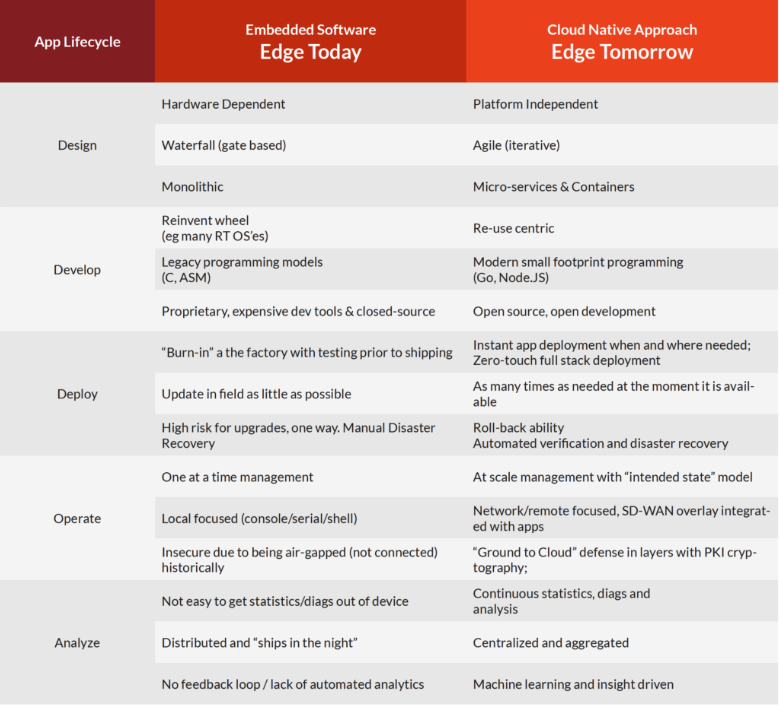
A comparison of legacy embedded and cloud-native edge software development
This cloud-native approach has allowed the largest cloud companies to achieve operations at hyperscale and is an absolute requirement for IoT to live up to its forecasted market value of over half a trillion dollars. To provide a view of what “hyperscale” will look like in edge computing, we need to look no further than the Meltdown bug discovered by Intel in January 2018. To protect customers from the effects of the bug, Amazon Web Services would have had to quickly patch some millions of servers to ensure smooth operations and security for all their customers (this is an estimate, as it is a proprietary number they don’t share). These fixes were not deployed in weeks or months, but hours and days.
Why is this approach needed for the edge? Ford Motor Company shipped 6.7 million cars in 2016. Some modern cars already have several servers with multiple software containers or virtual machines running on them, but they are not connected to the internet. For the smart car of the future (with Wi-Fi access, vehicle-to-vehicle exchange of sensor data, or even just map updating), there is an inevitable scenario for edge computing where a single car company could have to deal with 10 times the number of upgrades required by a cloud company the size of Amazon to protect their customers, because connecting the internet to these cars instantly makes them require continual updates and improvements. How does a car company scale its operations to deal with these compute and app problems? Are they going to increase their IT team to match Amazon Web Services? These are the realities of dealing with hyperscale at the edge.
Jargon-y? Sure. Making a real impact on business outcomes? Absolutely.